はじめに:知識を行動に変える
このコースでは、Optumアルゴリズムの人種バイアス(レッスン1)、公平性指標と不可能定理(レッスン2)、バイアス軽減手法(レッスン3)、医療特有の公平性評価(レッスン4)、ベストプラクティス(レッスン5)を学びました。
この最終レッスンでは、これらの知識を実践的なワークフローとして統合し、AI医療機器の開発・評価・導入・運用の各段階で「具体的に何をするか」を明確にします。
フェーズ1: 計画:公平性の目標を最初に定義する
1.1 保護属性の特定
プロジェクト開始時に、自施設の患者集団と臨床文脈に基づいて保護属性を特定:
- 臨床的に重要なサブグループは何か(性別、年齢、人種、基礎疾患等)
- 自施設の患者集団と学習データの患者集団に乖離はないか
- 法的・倫理的に保護すべき属性は何か
1.2 公平性指標の選択
視点
指標選択のガイドライン
- スクリーニング(早期発見): 等化オッズを優先。見逃し(偽陰性)の格差が患者の生命に直結するため。
- トリアージ(優先順位付け): 等化オッズ + 予測値パリティ。見逃しと誤報の両方が重要。
- 治療推奨: 個別公平性を重視。類似した患者に類似した治療を推奨すべき。
- リスク予測: 予測値パリティ。「高リスク」と判定された患者の実際のリスクがグループ間で同等であることが重要。
1.3 許容範囲の設定
公平性指標のグループ間差の許容範囲を事前に定義:
- 感度差: ±5ポイント以内(目安)
- 偽陽性率差: ±5ポイント以内(目安)
- これらの基準は臨床的文脈に応じて調整
フェーズ2: 開発:公平性を設計に組み込む
2.1 データの準備と監査
- データの構成を分析: 保護属性ごとのサンプル数・ラベル分布を確認
- データシートを作成: Gebru et al.のフォーマットに準拠
- 不均衡への対策: 必要に応じてリサンプリング・データ拡張を実施
- 代理変数のチェック: 保護属性と強く相関する変数(郵便番号、保険種類等)を特定
2.2 モデルの学習と公平性制約
- ベースラインモデル: まず標準的な方法でモデルを学習
- サブグループ別性能を計算: ベースラインでのバイアスの程度を把握
- 軽減手法を適用: 必要に応じて公平性制約付き最適化、敵対的デバイアシング等を実施
- 複数のモデルを比較: 精度と公平性のトレードオフを可視化
フェーズ3: 評価:徹底的な検証
3.1 内部検証
| 検証項目 | 方法 | 基準 |
|---|---|---|
| 全体性能 | 独立した検証データセットで評価 | 臨床的閾値を超えている |
| サブグループ性能 | 保護属性別に評価 | グループ間差が許容範囲内 |
| 公平性指標 | 事前選択した指標を計算 | 事前定義した基準を満たす |
| 交差分析 | 複数属性の組み合わせで評価 | 交差バイアスが許容範囲内 |
3.2 外部検証
- 異なる施設のデータで性能を確認(一般化可能性)
- 異なる時期のデータで性能を確認(時間的安定性)
- 異なる患者集団のデータで性能を確認(母集団の移行可能性)
3.3 モデルカードの完成
内部・外部検証の結果をモデルカードに記載。意図された用途、限界事項、サブグループ別性能を明記。
Optumアルゴリズム修正の全プロセス:バイアス検出から84%削減まで
検出: Obermeyerらが「同じリスクスコアの黒人患者が白人患者より26%多くの慢性疾患を持つ」ことを発見(サブグループ分析)。
原因分析: 「医療費」が健康状態の代理指標として使われていたが、歴史的な医療アクセス格差により、黒人患者の医療費が低かった(代理変数のバイアス)。
修正: 代理指標を「医療費」から「健康状態を直接反映する指標」(活動性の慢性疾患数等)に変更(データレベルの軽減)。
検証: 修正後、追加ケアを受けるべき黒人患者の割合が17.7%→46.5%に上昇。バイアスを84%削減。
教訓: このプロセスは本コースの4フェーズに対応: 検出(フェーズ3)→原因分析(フェーズ2に遡及)→修正(フェーズ2の再実行)→検証(フェーズ3の再実行)。
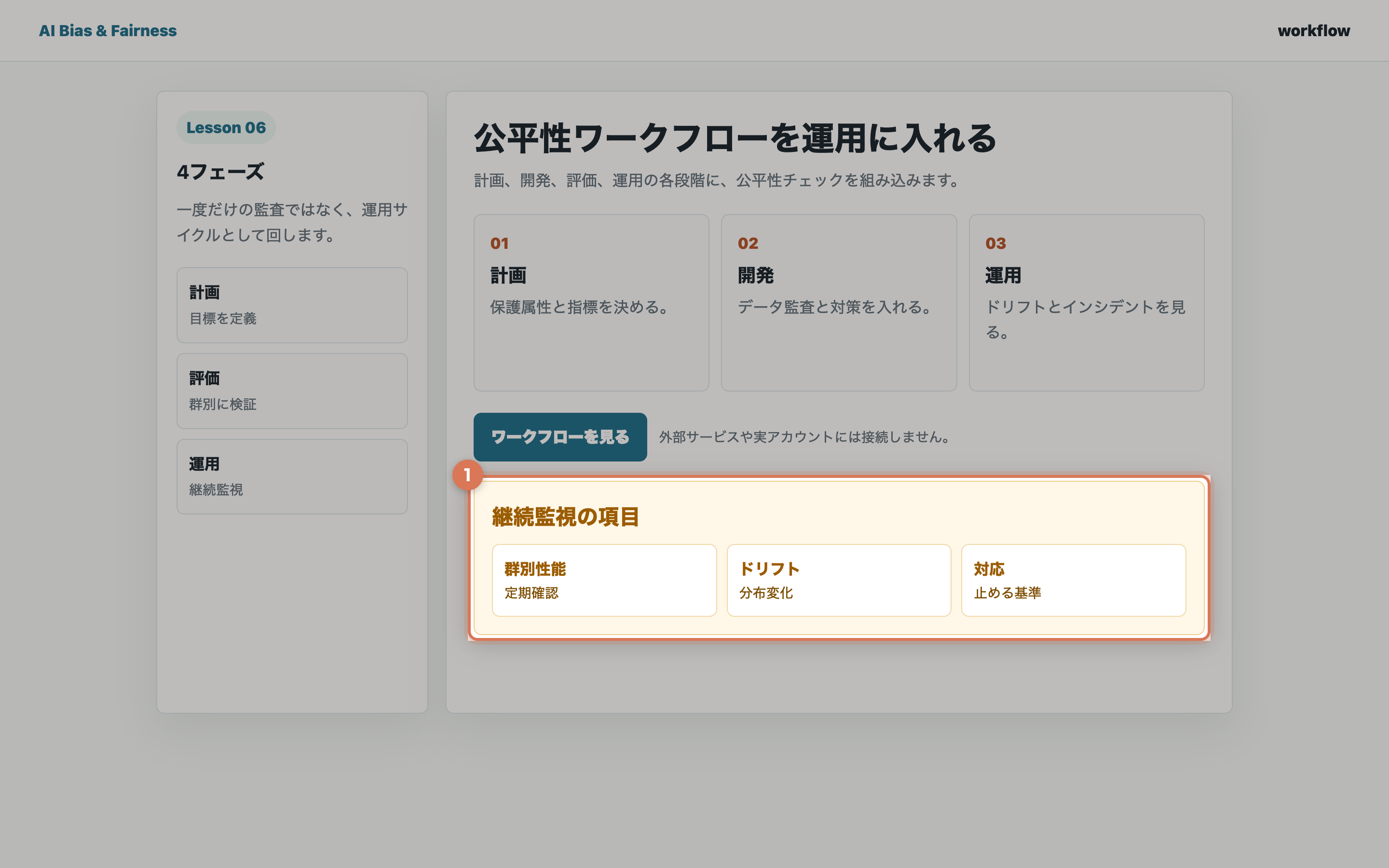
フェーズ4: 運用:継続的な監視と改善
4.1 定期的なサブグループ別モニタリング
- 月次: AIの判定結果のサブグループ別分布を確認
- 四半期: サブグループ別の性能指標を計算し、ベースラインと比較
- 年次: 外部データでの再検証と公平性の包括的レビュー
4.2 データドリフトの検出
- 入力データの分布が学習時から変化していないか監視
- 新たなサブグループ(新しい患者集団等)の出現をチェック
- COVID-19パンデミックのような大きな環境変化に注意
4.3 インシデント対応
公平性に関するインシデント(特定グループでの顕著な性能低下等)が発見された場合:
- 即時対応: 影響の範囲を評価し、必要に応じてAIの使用を一時停止
- 原因分析: データドリフト、新たなバイアス、モデルの劣化を調査
- 改善: 原因に応じた対策(データの更新、モデルの再学習、閾値の調整等)
- 再検証: 改善後のサブグループ別性能を確認
- 報告: インシデントと対応策を文書化し関係者に共有
コース全体のまとめ
このコース「AIのバイアスと公平性」で学んだ6つのレッスンを振り返ります:
| レッスン | 核心 | キーワード |
|---|---|---|
| 1. バイアスとは何か | AIは社会の不公平を学習し増幅する | Optum、皮膚科AI、パルスオキシメーター |
| 2. 検出方法 | サブグループ分析と公平性指標 | 等化オッズ、不可能定理、AIF360 |
| 3. 軽減手法 | データ・アルゴリズム・後処理の3層で対処 | 84%削減、DDI、敵対的デバイアシング |
| 4. 医療での公平性評価 | 臨床的文脈での公平性の意味 | eGFR、COMPAS、有病率の違い |
| 5. ベストプラクティス | 透明性と組織的取り組み | モデルカード、GMLP、WHO |
| 6. 実践的ワークフロー | 計画→開発→評価→運用の4フェーズ | 継続的監視、データドリフト |
最後に: 完璧な公平性は数学的に不可能な場合もあります。しかし、「どの公平性を優先するか」を意識的に選び、継続的にモニタリングし、透明に報告することは可能です。それが、すべての患者に公平な医療を提供するためにAI開発者と医療従事者が果たすべき責任です。
明日のアクション
現在進行中または計画中のAIプロジェクトについて、本コースの4フェーズ(計画・開発・評価・運用)に基づく「公平性チェックリスト」を1ページで作成しましょう。各フェーズで「保護する属性」「使用する公平性指標」「許容範囲」「監視頻度」を明記した計画書を作ることで、プロジェクト全体を通じた公平性の確保が可能になります。