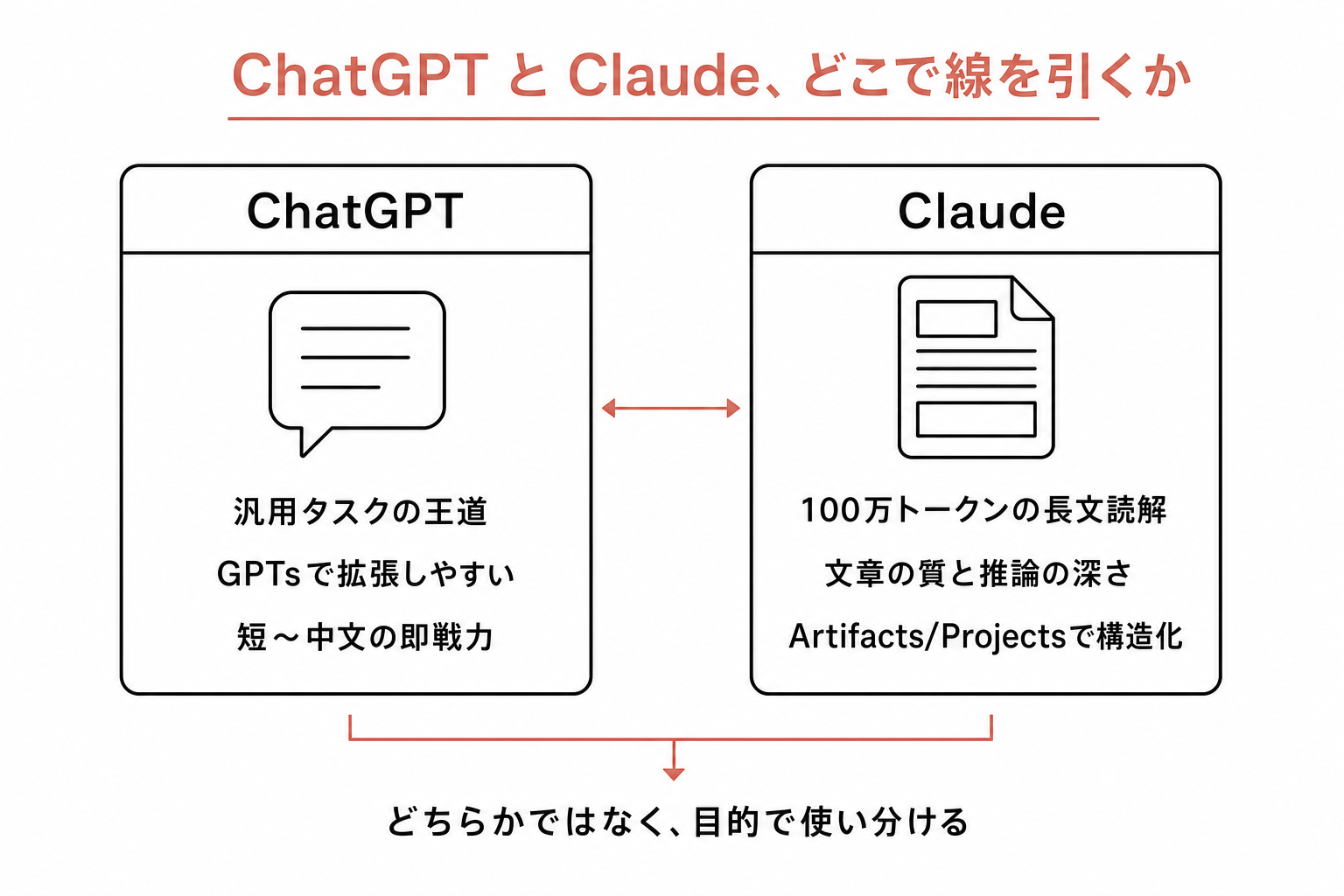

ChatGPTとは何が違うのか
ChatGPTが汎用タスクの入口として強い一方で、Claudeは長文の読み書きに寄った相棒だ。
両方使っている医師の結論はだいたい同じところに落ち着く。「タスク(検索、画像、音声)はChatGPT。思考(推論、執筆、要約)はClaude」[1]。
医師向け連載でも、ChatGPTのGPTsとClaude Opusを用途で使い分ける考え方が紹介されている [2]。
数字で見るClaudeの実力
以下は2024〜2026年時点の査読論文・研究報告に基づく数値です。モデル世代が進むにつれて数値も変化するため、傾向の参考としてご覧ください。
| 試験・ベンチマーク | Claude | 比較対象 | 出典 |
|---|---|---|---|
| USMLE Step 3 | 90% | ChatGPT 92% | AEI 2024 [3] |
| 歯科診断(117症例) | 91.5% | ChatGPT 74.4% | PMC 2025 [4] |
| ポーランド医師国試 | 全カテゴリ1位 | ChatGPT, Gemini | Nature Sci Rep 2025 [5] |
| MedAgentBench(臨床タスク) | 69.67%(1位/12モデル) | GPT-4o 64.00% | Stanford/NEJM AI 2025 [6] |
| PrIME-LLM(臨床推論) | トップクラスタ | 同世代GPT, Geminiと同等 | 2026 [7] |
注目すべきはMedAgentBenchだ。スタンフォード大学がFHIRベースの仮想EHR(78万5千件のレコード、100名の患者プロファイル)上で300の臨床タスク(検査オーダー、処方、データ検索)を実行させた。12モデル中、Claudeが1位(2025年時点のSonnetシリーズ)[6]。
単に「試験問題が解ける」ではなく、「実際の電子カルテを操作するタスクで最も正確」だったということだ。
Claudeの3つの武器
1. 圧倒的な文脈保持:最大100万トークン
ChatGPTのコンテキストウィンドウが12.8万トークンなのに対し、Claudeは最大100万トークン(約75万語)を一度に読める。80ページのガイドラインを丸ごと貼っても精度が落ちない。
これが臨床で何を意味するか。ガイドラインの「あの項目はどこに書いてあったっけ」を自然言語で聞ける。複数の論文を同時に入れて横断分析ができる。
2. 文章の質
Claude の文章は「的確で、冗長でない」と評価されることが多い。ある医師は月1万円を各AIに課金して1ヶ月間比較し、「文章の構成力と要約力が他のAIと比べて頭一つ抜けている」「論文の要約やスライド構成で圧倒的な品質」と結論づけている [8]。
3. Artifacts:インタラクティブなツールが即座に作れる
Claudeには「Artifacts」という機能がある。会話の中でHTMLアプリ、グラフ、ダッシュボードを即座に生成できる。レッスン3で詳しく扱う。
Claudeの限界
画像生成ができない。 ChatGPTのDALL-Eのような画像生成機能はない。テキスト処理に特化している。
リアルタイム検索ができない(制限あり)。 ChatGPTのようなウェブブラウジングは限定的。最新のニュースや論文を探すにはChatGPTかGeminiのほうが向いている。
ハルシネーションは起きる。 NotebookLMのように「自分の資料の中だけから答える」設計ではないので、存在しない情報を生成する可能性はある。出力は必ず確認する。
まとめ
- Claudeは「長文読解・構造化・執筆」で強みを発揮する
- 臨床タスクベンチマークで12モデル中1位(Stanford/NEJM AI)
- 100万トークンの文脈保持で、ガイドライン丸ごと投入が可能
- ChatGPTと競合ではなく補完。使い分けが正解
参考文献
- iatrox.com. ChatGPT vs Claude Medicine. 2025.
- 日経メディカル「こちら呼吸器病棟」. 2024.
- AEI. How Well Can AI Chatbots Mimic Doctors. 2024.
- PMC. Claude vs ChatGPT dental diagnosis. 2025. PMC12823890.
- Nature Scientific Reports. Polish medical exam comparison. 2025. doi:10.1038/s41598-025-17030-0.
- Jiang Y, et al. MedAgentBench. Stanford HAI / NEJM AI. 2025.
- News-Medical. PrIME-LLM clinical reasoning study. April 2026.
- casestock.work. note.com, 2024.