このレッスンで学ぶこと
このレッスンを完了すると、交差検証の仕組み、ハイパーパラメータ調整の手法、バイアスとバリアンスのトレードオフ、そしてモデル選択の基準を理解できるようになります。
セクション1: 交差検証
交差検証とは
交差検証(Cross-validation)は、データを複数のグループに分けて、モデルの性能をより信頼性高く評価する手法です。
k-fold交差検証
最もよく使われる交差検証の方法です:
- データをk個のグループ(fold)に分割する
- 1つのfoldをテスト用、残りのk-1個を訓練用にして学習・評価する
- テスト用のfoldを順に変えて、k回繰り返す
- k回の評価結果の平均を最終的な性能とする
交差検証の利点:
- 信頼性:1回の分割だけに依存しないため、より安定した評価が得られる
- データの有効活用:全てのデータが訓練とテストの両方に使われる
- 過学習の検出:訓練スコアと検証スコアの差から過学習を検出できる
注意
医療データでの交差検証の注意点
医療データでは、同一患者の複数レコードが異なるfoldに分かれてしまう「データリーケージ」に注意が必要です。患者単位でfoldを分割する「グループk-fold交差検証」を使いましょう。また、時系列データの場合は、未来のデータで過去を予測してしまわないよう、時系列を考慮した分割(Time Series Split)が必要です。
Leave-One-Out交差検証(LOOCV)
データの各サンプルを1つずつテスト用にして、残り全てで学習する方法です。サンプル数が少ない場合(例:希少疾患の研究)に有用ですが、計算コストが高いのが難点です。
セクション2: ハイパーパラメータ調整
ハイパーパラメータとは
ハイパーパラメータは、モデルの学習を始める前に人間が設定するパラメータです。データからは自動的に学習されず、モデルの振る舞いを外側から制御します。
ハイパーパラメータの例:
- 学習率:モデルが1回の更新でどれだけ学習するか
- 正則化係数:過学習をどの程度抑制するか
- 決定木の最大深さ:木の構造をどこまで複雑にするか
- ニューラルネットワークの層数・ニューロン数:モデルの表現力
調整手法
グリッドサーチ: あらかじめ定義したパラメータの組み合わせを全て試す。確実だが、パラメータが増えると計算量が指数的に増加する。
ランダムサーチ: パラメータ空間からランダムにサンプリングして試す。グリッドサーチより効率的で、同じ計算予算ならより良い結果が得られることが多い。
ベイズ最適化: 過去の試行結果を基に、次に試すべきパラメータを確率モデルで推定する。少ない試行回数で効率的に最適値に近づける。
比較
グリッドサーチ vs ランダムサーチ
パラメータが2〜3個なら、グリッドサーチで網羅的に探索するのが確実です。しかし、パラメータが4個以上になると、全ての組み合わせを試すのは現実的でなくなります。研究では、ランダムサーチの方が同じ計算時間でより良い結果を見つけやすいことが示されています(Bergstra & Bengio, 2012)。
セクション3: バイアスとバリアンスのトレードオフ
バイアスとバリアンスとは
バイアス(Bias):モデルの予測の系統的な偏り。モデルが単純すぎて、データの真のパターンを捉えきれない場合に高くなる(学習不足 / Underfitting)。
バリアンス(Variance):モデルの予測のばらつき。訓練データが変わるとモデルの予測が大きく変わる場合に高くなる(過学習 / Overfitting)。
トレードオフの理解
バイアスとバリアンスは一般にトレードオフの関係にあります:
- モデルが単純すぎる場合:高バイアス・低バリアンス → 学習不足
- モデルが複雑すぎる場合:低バイアス・高バリアンス → 過学習
- 最適なモデル:バイアスとバリアンスの合計誤差が最小となるバランス
視点
医療AIにおけるバイアス-バリアンスの実践的意味
診断支援AIでは、このトレードオフが臨床的に重要な意味を持ちます。高バイアス(学習不足)のモデルはデータのパターンを十分に捉えられず、高バリアンス(過学習)のモデルは新しいデータへの汎化が不安定になります。感度や特異度のどちらが影響を受けるかは、分類閾値やクラス分布に依存するため一概には言えません。臨床でのコスト(見落としのコスト vs 偽陽性のコスト)を考慮して閾値とモデルの複雑さを調整する必要があります。
セクション4: モデル選択
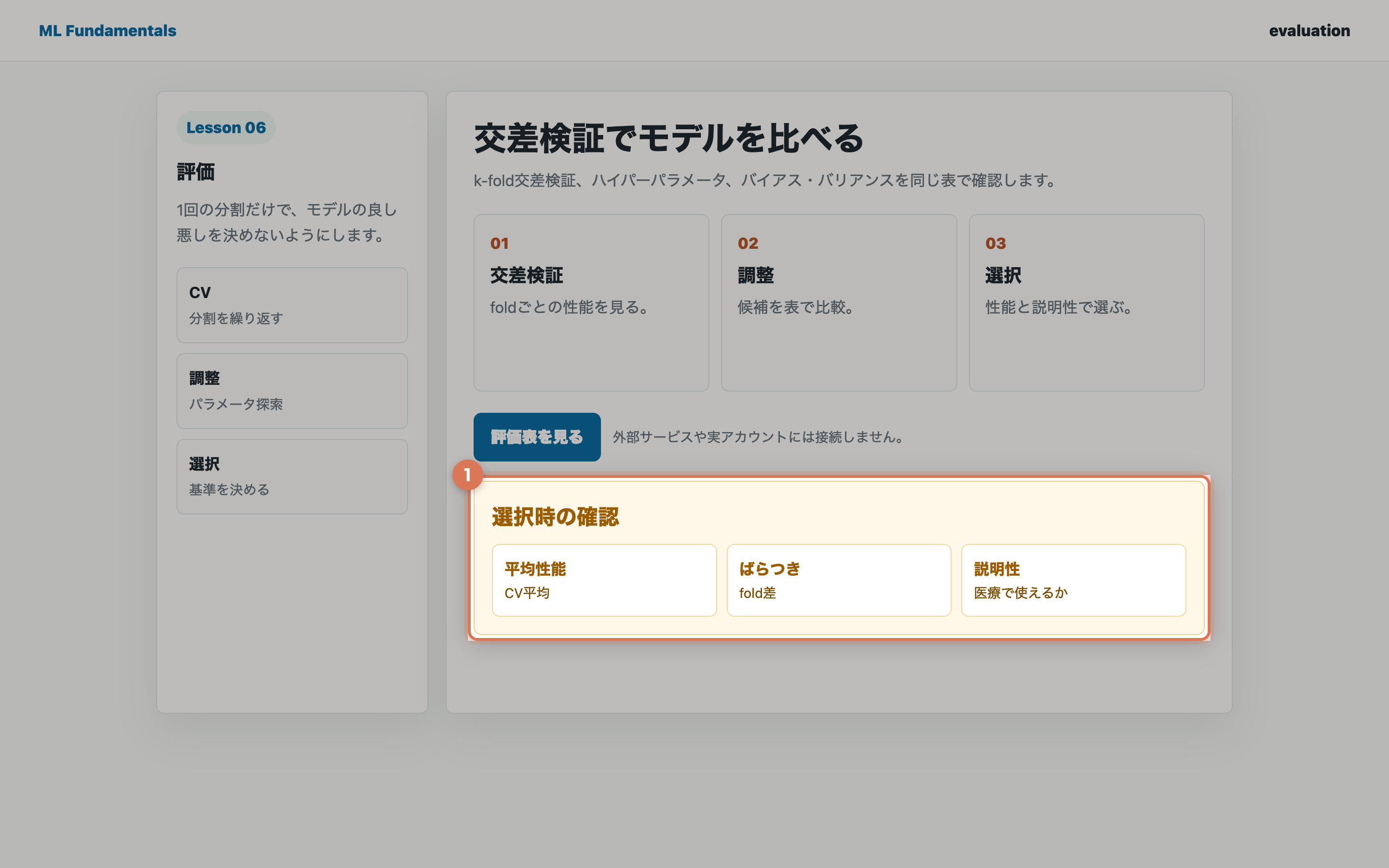
モデル選択の基準
複数の候補モデルから最適なものを選ぶ際には、性能だけでなく複数の基準を総合的に判断します。
主な選択基準:
- 予測性能:テストデータでの評価指標(AUC、F1スコア等)
- 解釈可能性:予測の根拠を人間が理解できるか
- 計算効率:訓練・推論にかかる時間とリソース
- データ要求量:十分な性能を発揮するのに必要なデータ量
- デプロイの容易さ:実運用環境での導入・保守のしやすさ
医療分野でのモデル選択
視点
説明可能性 vs 精度のジレンマ
医療では、高精度なブラックボックスモデル(深層学習等)と、やや精度は劣るが説明可能なモデル(ロジスティック回帰、決定木等)のどちらを選ぶかが常に議論されます。臨床ガイドラインの策定や規制当局の承認には説明可能性が求められますが、画像診断など一部の用途では精度が最優先される場合もあります。
まとめ
このレッスンでは、モデルの評価と改善の手法を学びました。
重要なポイント:
- 交差検証:データを複数のfoldに分けて信頼性の高い評価を行う
- ハイパーパラメータ調整:グリッドサーチ、ランダムサーチ、ベイズ最適化で最適なパラメータを探索
- バイアスとバリアンス:学習不足(高バイアス)と過学習(高バリアンス)のバランスが重要
- モデル選択:性能だけでなく、解釈可能性・計算効率・実用性を総合的に判断する
明日のアクション
2つの診断支援モデルがあるとします。モデルA(ロジスティック回帰)はAUC 0.85で特徴量の寄与が明確に説明可能。モデルB(深層学習)はAUC 0.92だが判断根拠が不透明。以下の3つのシナリオでどちらを選ぶか、理由とともに考えてみましょう:(1) 救急外来のトリアージ、(2) 臨床ガイドラインへの組み込み、(3) 画像診断の二次読影支援。
参考文献
- Bergstra J, Bengio Y. Random search for hyper-parameter optimization. J Mach Learn Res. 2012;13:281-305. https://jmlr.org/papers/v13/bergstra12a.html