はじめに:同じ病気なのに、肌の色で結果が変わる
2019年、Science誌に衝撃的な論文が掲載されました。米国の医療システムで数百万人の患者に適用されていたリスク予測アルゴリズムが、同じ健康状態の黒人患者を白人患者よりも系統的に「低リスク」と判定していたのです。
原因は意外にシンプルでした。アルゴリズムが「医療費」を健康状態の代理指標として使用していたのです。しかし、歴史的に医療アクセスが制限されてきた黒人患者は、同じ病気でも医療費が低い傾向がありました。結果として、同じリスクスコアの黒人患者は白人患者より平均26%多くの慢性疾患を抱えていました。
AIは人間の偏見を学習し、増幅します。そしてそれは、患者の生死に関わる判断に影響を及ぼします。
医療リスク予測AIの人種バイアスを実証した画期的論文。アルゴリズム修正によりバイアスを84%削減
AIにおけるバイアスの種類
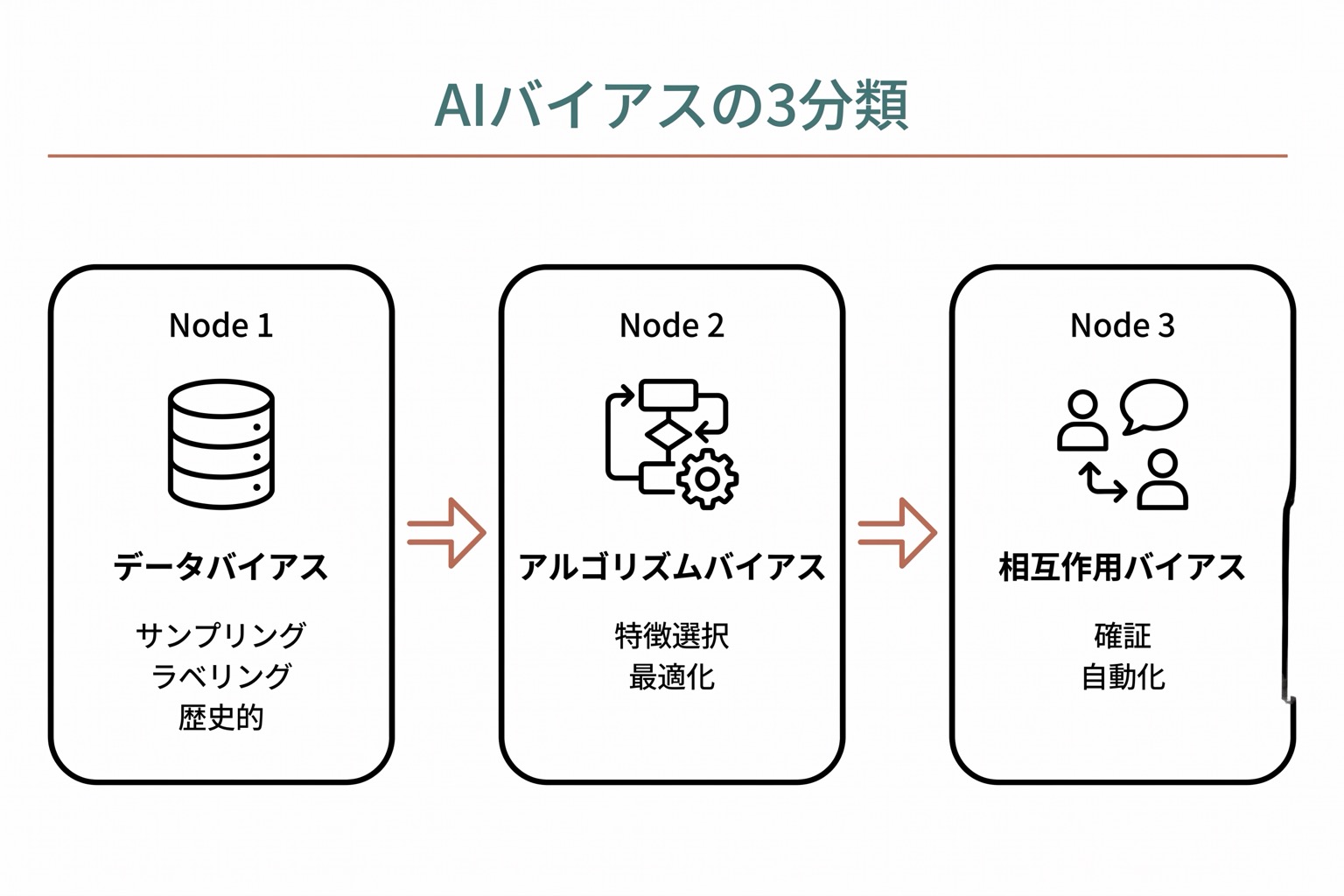
データバイアス
学習データが現実世界の多様性を正確に反映していない場合に生じます。
- サンプリングバイアス: 学習データが特定の人口集団に偏る
- ラベリングバイアス: データにラベルを付ける人間の偏見が反映される
- 歴史的バイアス: 過去の不公平な医療実践がデータに残る
アルゴリズムバイアス
AIモデルの設計・最適化過程で生じます。
- 特徴選択バイアス: 人種や性別など倫理的に問題のある特徴を過度に重視
- 最適化バイアス: 多数派の精度を最大化する結果、少数派の精度が犠牲になる
相互作用バイアス
AIと人間の相互作用の中で生じます。
- 確証バイアス: AIの推奨を過度に信頼し、反する証拠を無視する
- 自動化バイアス: AIの判断を批判的に評価せず受け入れてしまう
実際に起きたこと:ケーススタディ
ケース1: 皮膚科AIの人種バイアス
皮膚科AIモデルのダークスキンでの精度低下
背景: Stanford大学のDaneshjouらは、多様な肌の色を含む656枚の皮膚画像データセット(DDI: Diverse Dermatology Images)を構築し、既存の皮膚科AIモデルの性能を評価しました。
何がわかったか:
- 既存の皮膚科AIモデルは、ダークスキンでの診断精度がROC-AUCで27-36%低下
- 公開されている皮膚疾患AIベンチマークに、ダークスキンの生検確認済み悪性腫瘍画像が1枚も含まれていなかった
- DDIデータセットでファインチューニングすることで、肌の色による精度差を大幅に縮小できた
なぜ問題か: メラノーマの死亡率は有色人種で高い傾向にあるが、これは部分的に診断の遅れに起因する。AIがこの格差を再生産・拡大するリスクがある。
多様な肌の色を含むDDIデータセットで皮膚科AIの性能格差を実証
ケース2: パルスオキシメーターの人種バイアス
パルスオキシメーター:肌の色による測定誤差
背景: New England Journal of Medicineに掲載された研究で、パルスオキシメーターが黒人患者の血中酸素飽和度を系統的に過大評価していることが示されました。
データ:
- パルスオキシメーターで92-96%と表示された患者のうち、動脈血ガスで実際に88%未満だった割合:
- 黒人患者: 11.7%
- 白人患者: 3.6%
- 黒人患者は白人患者の約3倍の頻度で、パルスオキシメーターで検出されない低酸素血症を有していた
原因: パルスオキシメーターは赤色光(660nm)と赤外光(940nm)の吸収差で測定するが、メラニンによる赤色光の吸収が考慮されていない。機器の較正段階でダークスキンの被験者が十分に含まれていなかった。
AI開発への教訓: 医療AIの学習データが特定の集団で偏っている場合、AIはこの種の機器バイアスをさらに増幅する可能性がある。パルスオキシメーターのデータを入力特徴量として使うAIは、黒人患者の低酸素血症を系統的に見逃しうる。
パルスオキシメーターの人種による測定バイアスを実証。FDAが改善を優先課題に指定
比較
「データの問題」か「社会の問題」か
パルスオキシメーター: 機器自体が暗い肌で不正確に設計された → その不正確なデータでAIを学習させる → AIがバイアスを引き継ぐ。
医療費アルゴリズム: 医療費データ自体は正確 → しかし社会的な医療アクセスの格差がデータに反映されている → AIが格差を「正常」として学習する。
→ バイアスは単一の原因ではなく、機器・社会構造・データ・アルゴリズムの複合的な問題。
バイアスの検出と測定
データの監査
学習データの構成を分析し、偏りがないか確認します:
- 人口統計学的バランス(人種、性別、年齢層の分布)
- 疾患の種類や重症度の分布
- データ収集の方法と時期
サブグループ分析
AIの性能を異なるサブグループごとに評価します。全体の精度が95%でも、特定のグループで85%に低下していれば、バイアスの存在が疑われます。
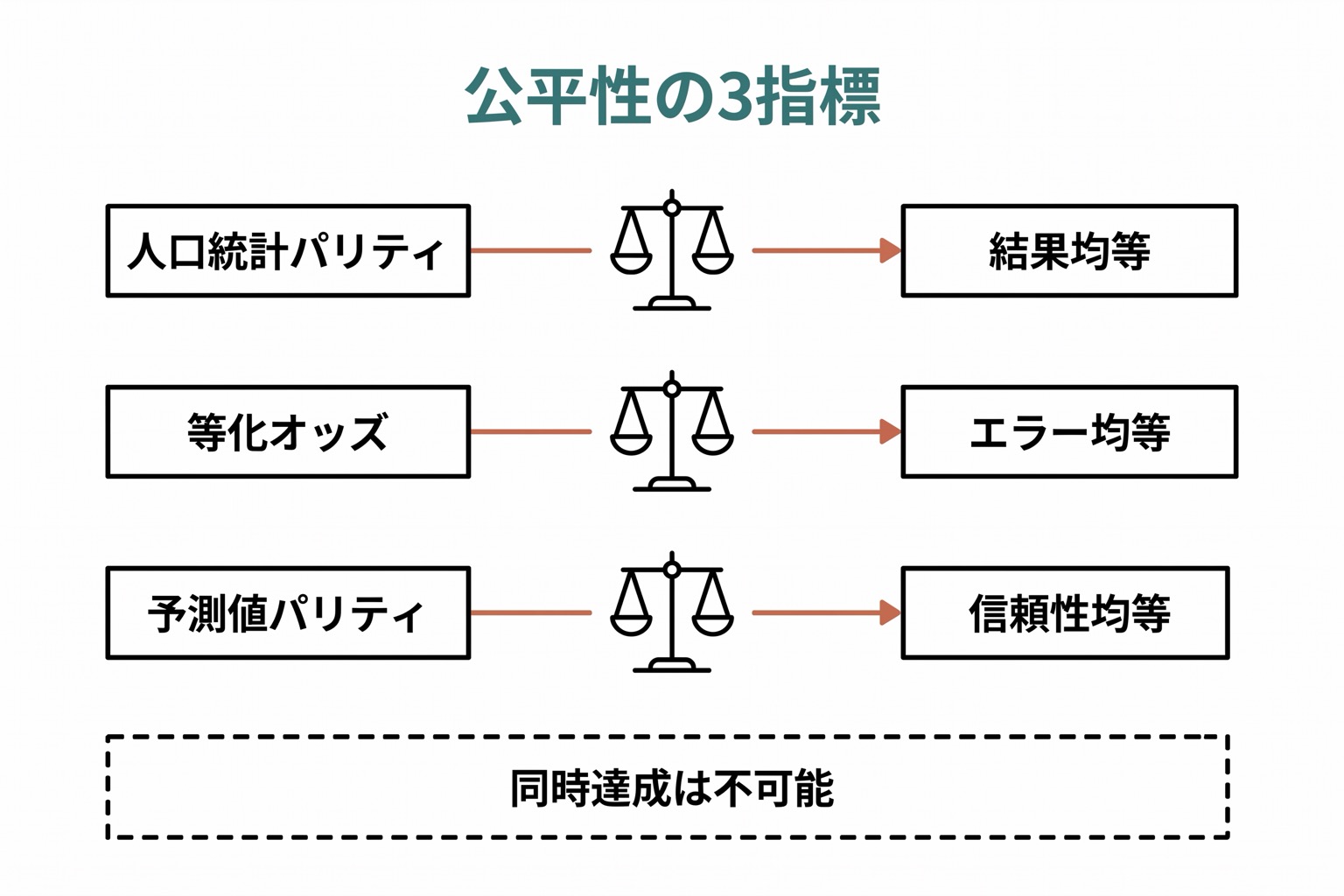
公平性指標
| 指標 | 定義 | 何を保証するか |
|---|---|---|
| 人口統計学的パリティ | すべてのグループで陽性判定の割合が等しい | 結果の均等 |
| 等化オッズ | すべてのグループで真陽性率と偽陽性率が等しい | エラーの均等 |
| 予測値パリティ | すべてのグループで陽性的中率が等しい | 予測の信頼性の均等 |
視点
公平性の不可能定理
これらの指標をすべて同時に満たすことは数学的に不可能な場合があることが証明されています(Kleinberg et al., 2016; Chouldechova, 2017)。つまり、「完全に公平なAI」は理論上存在しない状況がある。重要なのは、どの公平性の定義を優先するかを意識的に選択し、その理由を透明に説明することです。
公平性を確保するための戦略
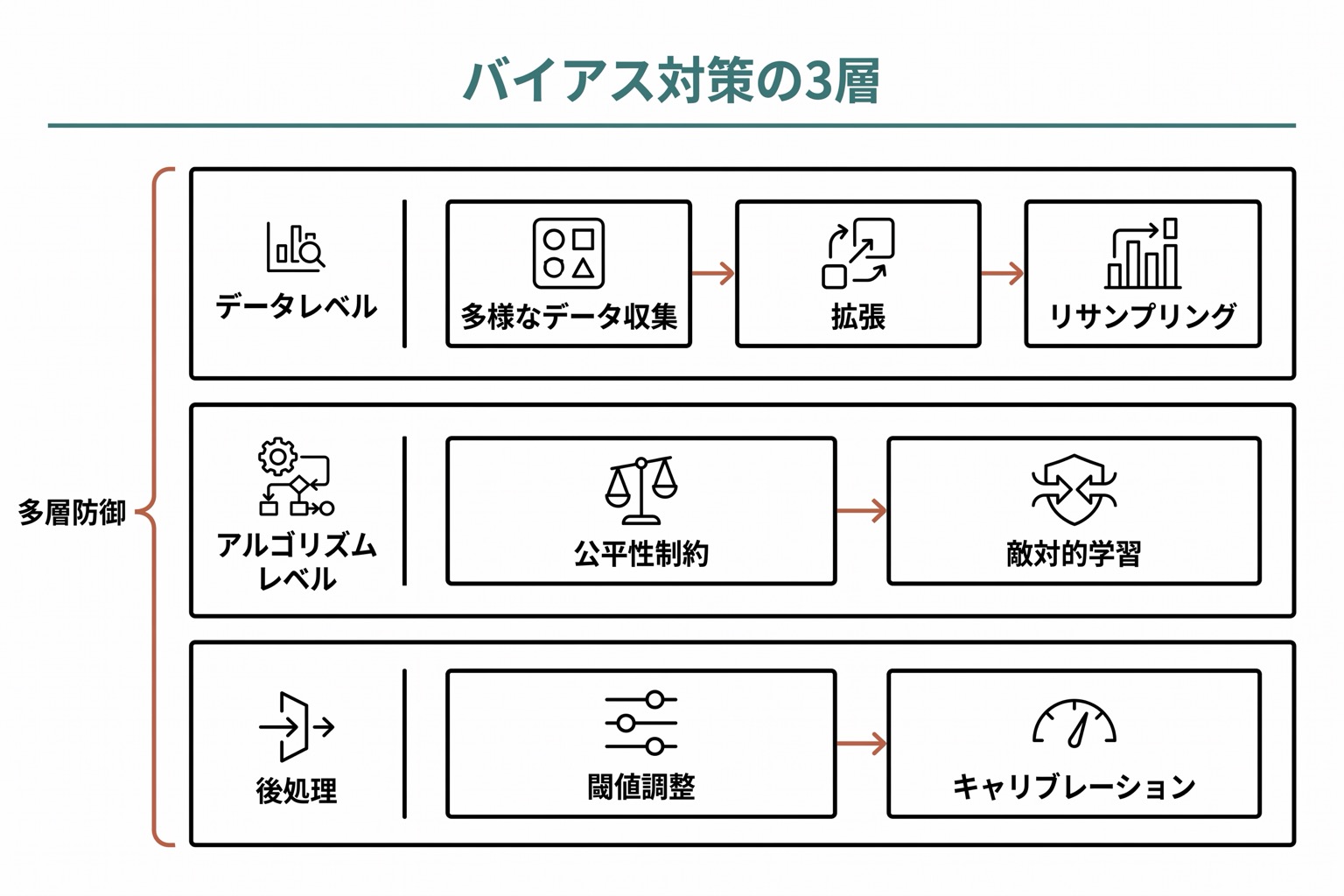
データレベルの対策
- 多様なデータの収集: すべての人口集団を適切に代表するデータを収集
- データ拡張: 少数派のデータを人工的に増やす技術
- リサンプリング: 多数派を減らすか、少数派を増やしてバランスを取る
アルゴリズムレベルの対策
- 公平性制約の導入: 学習時に公平性指標を制約条件として組み込む
- 敵対的デバイアシング: 保護属性(人種、性別等)を予測できないようにする技術
- サブグループ別モデル: 異なる集団に対してそれぞれ最適化されたモデルを使用
ポストプロセッシング
- 閾値の調整: グループごとに判定の閾値を調整
- キャリブレーション: モデルの出力確率を実際の確率に合わせる
Google研究者らが提唱したモデルカードの概念。バイアス評価結果の透明な文書化を推進
人間の監督
- 多様なチームの編成: 異なる背景を持つメンバーをAI開発チームに含める
- 継続的な監視: 運用開始後も定期的にサブグループ別性能を監視
- フィードバック収集: ユーザーや患者からのフィードバックを継続的に収集
問い
考えてみよう
Obermeyerらの研究では、アルゴリズムの修正によりバイアスを84%削減できました。しかし、修正前のアルゴリズムは何年も使われ、その間に「追加ケアが必要」と判定されるべきだった黒人患者の割合は17.7%にとどまっていました(修正後は46.5%に上昇)。
あなたの施設で使用している予測モデルやAIツールは、どの人口集団で検証されていますか? ベンダーにサブグループ別の性能データを確認したことはありますか?
まとめ
AIは人間の偏見を反映し、増幅します。Obermeyerらの研究は、一見「客観的」に見えるアルゴリズムが、歴史的な社会構造の不公平を再生産しうることを示しました。皮膚科AIやパルスオキシメーターの事例は、バイアスがデータ・機器・社会構造の複合的な問題であることを明らかにしています。
完璧な公平性は数学的に不可能な場合もありますが、だからこそ「何を公平と定義するか」を意識的に選び、継続的にモニタリングし、透明に報告することが求められます。
次のレッスンでは、AIの説明可能性と透明性について学びます。
明日のアクション
自施設で使用している診断支援AIや予測モデルについて、患者の人種・性別・年齢層ごとの精度(感度・特異度)を確認してみましょう。ベンダーにサブグループ別の性能データを問い合わせ、特定の集団で精度が低下していないかを検証することが、公平な医療の第一歩です。