このレッスンで学ぶこと
このレッスンを完了すると、強化学習の基本概念(エージェント・環境・報酬・方策)と、医療分野での応用可能性を理解できるようになります。
セクション1: エージェントと環境
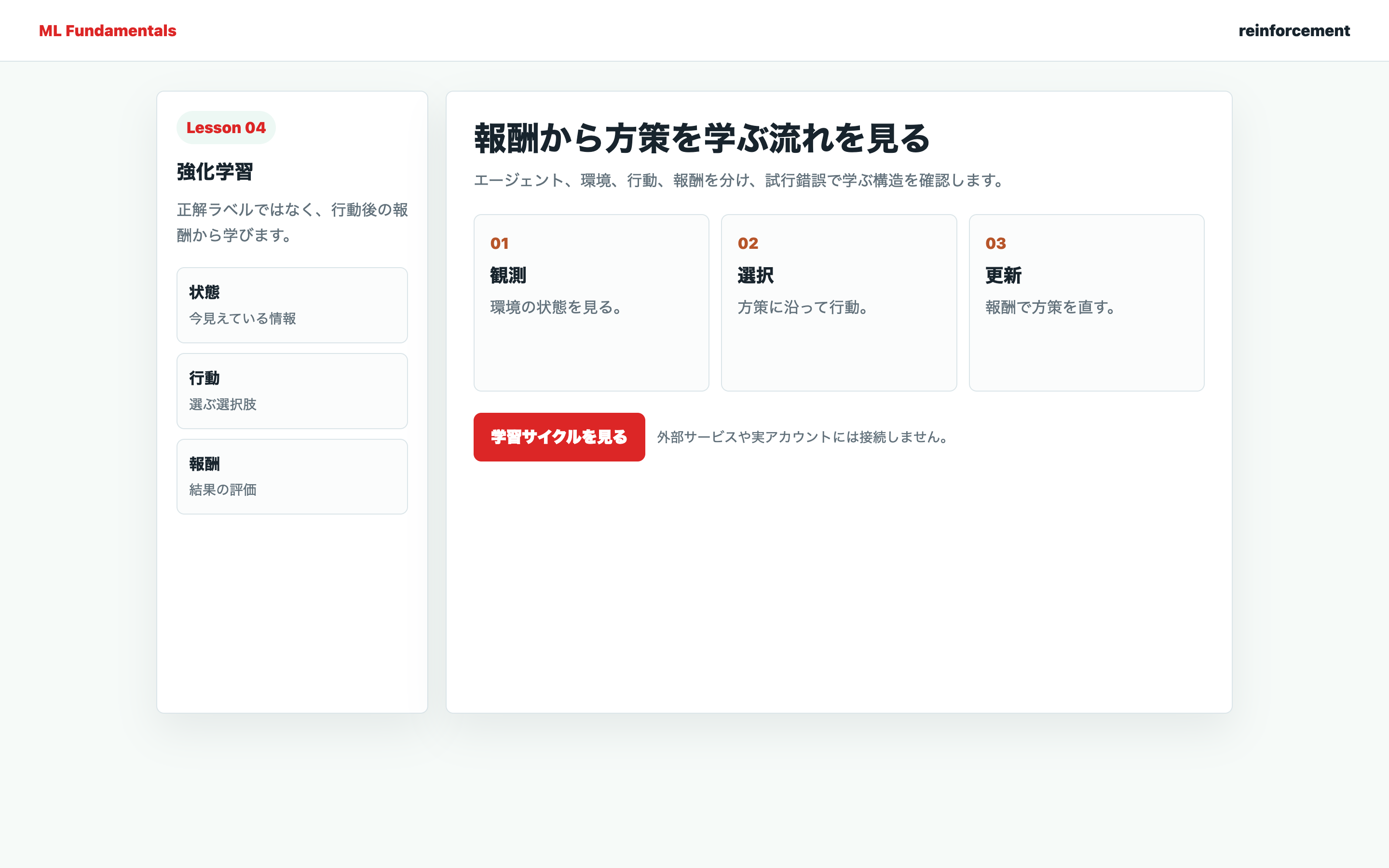
強化学習のフレームワーク
強化学習は、教師あり学習や教師なし学習とは根本的に異なるアプローチです。正解データを直接与えるのではなく、「試行錯誤」を通じて最適な行動を学習します。
エージェント
エージェントは、学習を行い行動を選択する主体です。
- 状態の観測:環境の現在の状態を観測する
- 行動の選択:観測した状態に基づいて行動を選択する
- 報酬からの学習:行動の結果得られる報酬を基にして、より良い行動を学習する
環境
環境は、エージェントが相互作用する対象です。
- 状態(State):環境の現在の状態を表す情報
- 報酬(Reward):エージェントの行動に対するフィードバック
- 遷移(Transition):行動によって状態がどう変化するかのルール
比較
強化学習 vs 教師あり学習
教師あり学習では「正解(ラベル)」が事前に与えられますが、強化学習では正解が与えられません。代わりに、行動の結果として「報酬」が返され、エージェントは累積報酬を最大化するように試行錯誤で学習します。これは、医師が臨床経験を積みながら最適な判断を身につけていく過程に似ています。
セクション2: 報酬と方策
報酬(Reward)
報酬は、エージェントの行動がどれだけ良かったかを示す数値的なフィードバックです。
報酬の種類:
- 即時報酬:行動直後に得られる報酬(例:薬を投与した直後の症状改善)
- 遅延報酬:行動のかなり後に得られる報酬(例:長期的な治療成績)
- 累積報酬:一連の行動を通じた報酬の合計
注意
報酬設計の難しさ
強化学習の成功は、報酬の設計に大きく依存します。医療では、「短期的な症状の改善」と「長期的な予後」のバランスをどう報酬に反映するかが難しい課題です。例えば、痛みを即座に抑えるオピオイドの投与は短期的には報酬が高くなりますが、依存リスクを考慮すると長期的には適切でない場合があります。
方策(Policy)
方策は、「ある状態でどの行動を選ぶか」を決めるルールです。
方策の特性:
- 状態→行動のマッピング:現在の状態に基づいて最適な行動を選択
- 最適方策の学習:累積報酬を最大化する方策を見つけるのが目標
- 探索と活用のバランス:未知の行動を試す「探索」と、既知の良い行動を使う「活用」のバランスが重要
探索と活用のジレンマ
エージェントは、以下の2つの戦略のバランスを取る必要があります:
- 探索(Exploration):まだ試していない行動を選んで、新しい知識を得る
- 活用(Exploitation):これまでの経験から最善と分かっている行動を選ぶ
セクション3: 医療分野での応用
治療方針の最適化
強化学習は、個々の患者に対する逐次的な意思決定の最適化に適しています。
視点
敗血症治療への応用
MITの研究チームは、ICUの敗血症患者に対する輸液量と昇圧剤の投与量を、強化学習で最適化する研究を行いました。AIが推奨する治療方針に従った場合の方が、実際の医師の判断よりも死亡率が低くなる可能性が示されています。ただし、これは後ろ向き研究であり、実臨床での検証はまだ十分ではありません。
応用例:
- 投薬量の最適化:患者の状態変化に応じた最適な投薬スケジュール
- リハビリ計画:回復状況に応じた最適な運動プログラムの設計
- 慢性疾患管理:糖尿病などの長期にわたるインスリン投与量の最適化
診断プロセスの最適化
限られたリソースの中で、効率的に診断にたどり着くプロセスも強化学習で最適化できます。
応用例:
- 検査オーダーの最適化:最小限の検査で最大限の診断情報を得る順序を学習
- 段階的な診断:確率の高い疾患から効率的に絞り込む戦略
- リソース配分:限られた医療資源の最適な配分
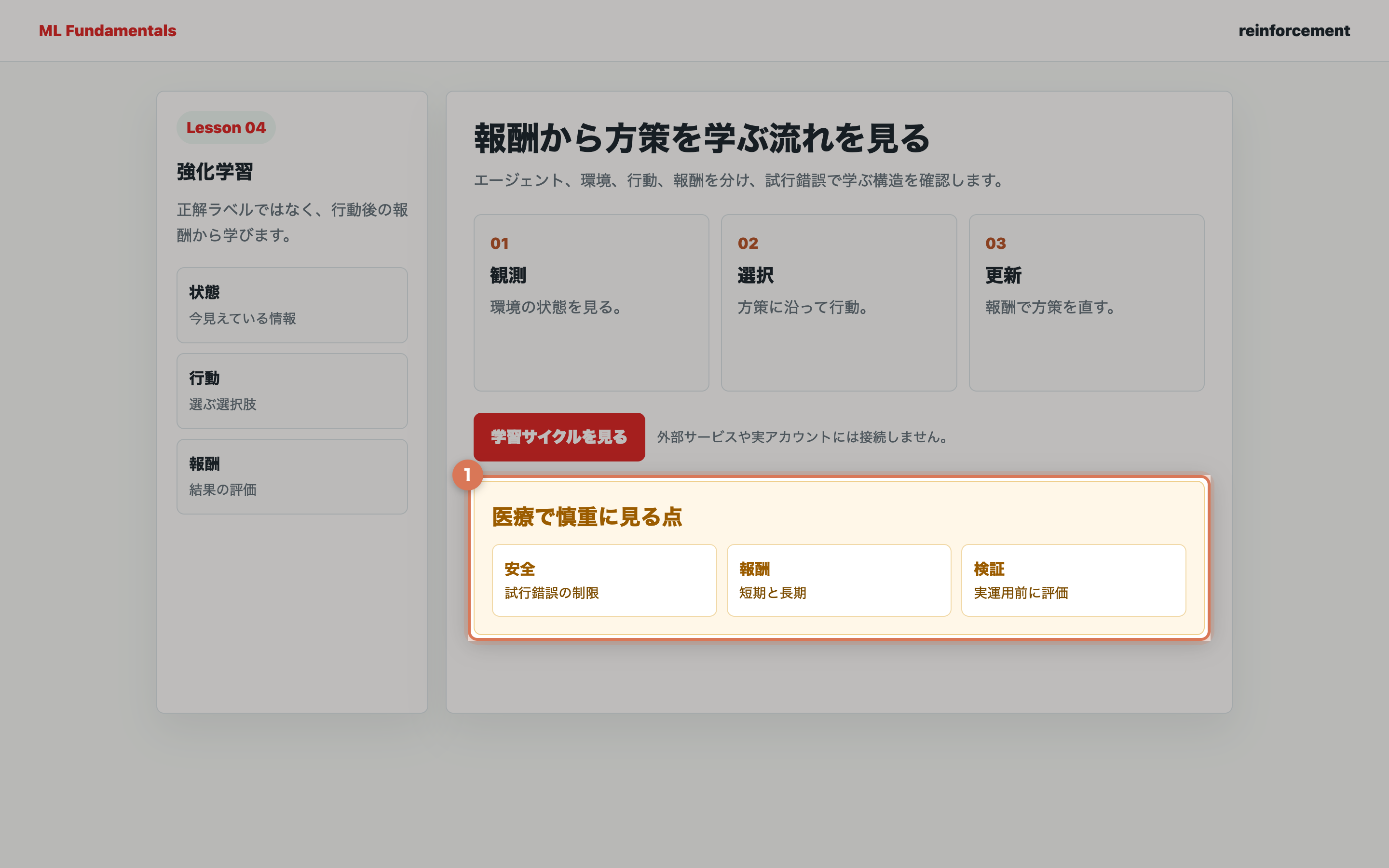
重要な洞察:強化学習の可能性と課題
強化学習は医療での意思決定を最適化する大きな可能性を持っていますが、実用化には課題も多くあります。
実践的なポイント:
- 安全性の担保:試行錯誤の過程で患者に害を与えることは許されない。シミュレーション環境での十分な検証が不可欠
- 説明可能性:なぜその治療方針を推奨するのか、医師や患者に説明できる必要がある
- データの制約:強化学習は大量の試行が必要だが、医療では実験的な試行には倫理的制約がある
まとめ
このレッスンでは、強化学習の基本概念を学びました。
重要なポイント:
- エージェントと環境:エージェントが環境と相互作用し、試行錯誤で学習する
- 報酬と方策:累積報酬を最大化する方策(行動ルール)を学習する
- 探索と活用:新しい行動の探索と既知の良い行動の活用のバランスが重要
- 医療応用:治療方針の最適化や診断プロセスの効率化に応用可能だが、安全性の確保が課題
明日のアクション
糖尿病患者のインスリン投与を強化学習で最適化するシナリオを考えてみましょう。「状態」「行動」「報酬」をそれぞれどう定義すればよいか、また安全性を確保するためにどのような制約を設けるべきかを書き出してみてください。
参考文献
- Komorowski M, Celi LA, Badawi O, Gordon AC, Faisal AA. The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nat Med. 2018;24(11):1716-1720. DOI 10.1038/s41591-018-0213-5