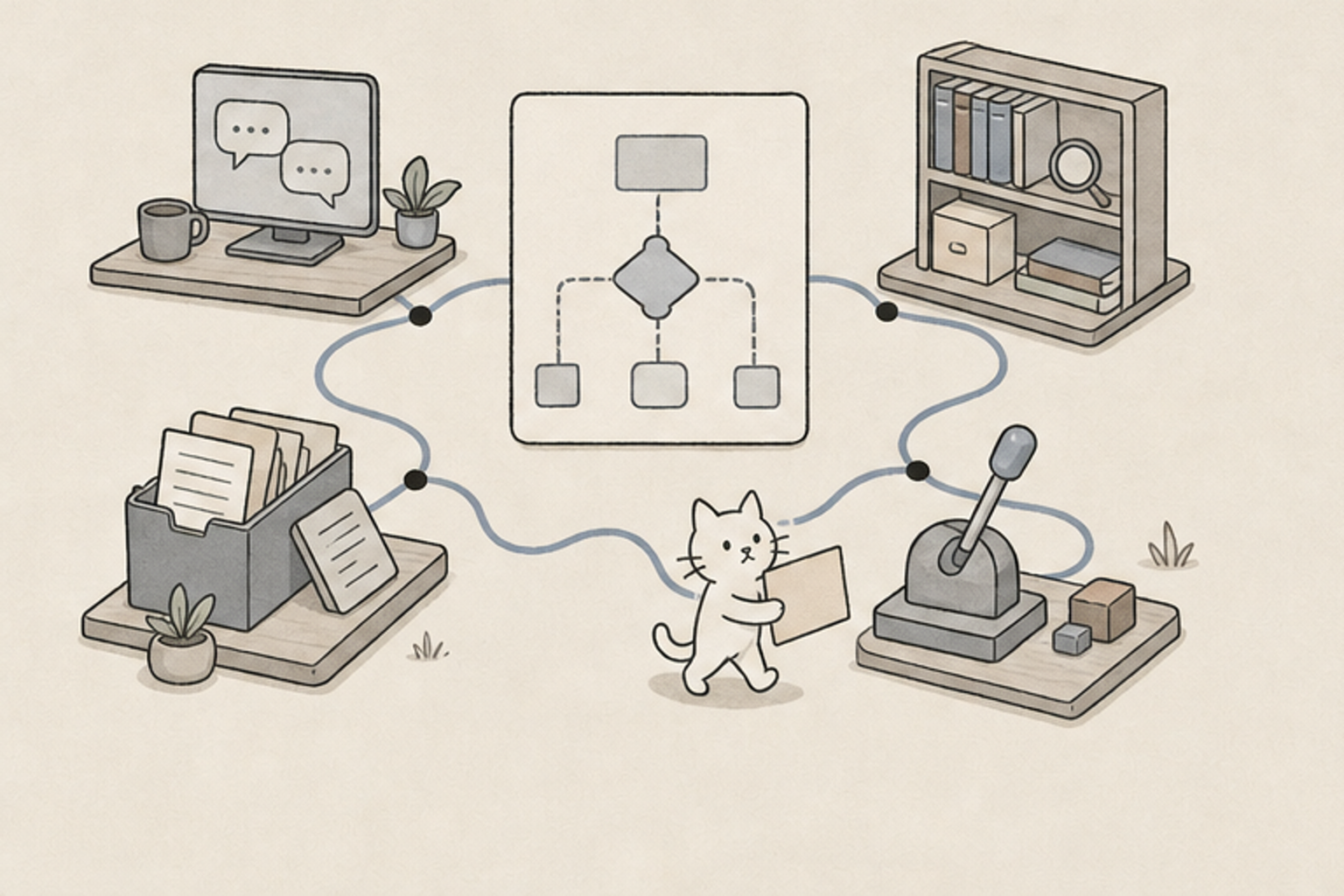
前回はLLMの仕組みとハルシネーションの正体を扱った。今回は実践に踏み込む。何を使えばいいのか。
汎用対話
ChatGPT
Claude
Gemini
何でも聞ける
文献検索
OpenEvidence
Consensus
引用付きで安心
自分の資料
NotebookLM
自分の本棚
エージェント
Genspark
Manus
自動で調査
はじめに:全部試す必要はない
研修医向けの勉強会をやると、必ず聞かれる。「ツールが多すぎて選べません」。気持ちは分かるが、答えはシンプルだ。文章生成、文献検索、資料統合、タスク自動化。この4目的を押さえて、各カテゴリから1つ手に馴染ませればいい。全部入れる必要はない。
以下、医療現場で実際に使われている主要ツールを目的別に整理する。
文章生成・対話の主軸:ChatGPT、Claude、Gemini
文章生成、要約、翻訳、コード補助。汎用LLMの3つはどれもこなす。差が出るのは細部だ。
ChatGPT(OpenAI)。現行モデルはGPT-4oおよびGPT-5。ユーザー数が最多で、画像認識・音声入力・外部ツール連携が一番こなれている。GPTsによる拡張性も高い。日本語も自然。
Claude(Anthropic)。現行のClaude 4シリーズ(Opus/Sonnet/Haiku)は長文の読み込みと文脈保持が強い。最大100万トークンのコンテキストウィンドウを持ち [1]、100ページのPDFを丸ごと貼っても精度が落ちにくい。論文通読やガイドラインの読み解きでは頭一つ抜ける。トーン指定がしやすく、執筆支援向き。
Gemini(Google)。現行はGemini 2.5/3 Pro。Google検索・YouTube・Driveとの連携が深い。最新情報のキャッチアップやウェブ資料の横断に向く。
比較
3つを使い分ける目安
- 対話・アイデア出し・コード補助 → ChatGPT
- 長文PDFの読解・論文要約・文章執筆 → Claude
- ウェブ検索を伴う最新情報・Google系資料の統合 → Gemini
→ 1つに絞る必要はない。同じ質問を2つに投げて答えを比較するだけでも、誤りに気づきやすくなる。
汎用LLMの代表格。画像認識・音声入力・プラグイン連携が充実
長文PDF読解と文脈保持に強い。論文要約・執筆支援に向く
文献・ガイドラインに特化:OpenEvidence、Consensus
ハルシネーションが一番痛いのは文献引用だ。存在しない論文を堂々と出されるとたまらない。ここに特化して解決しにきたのが医療特化型ツールである。
OpenEvidence。PubMedとガイドラインだけを引用元にして臨床疑問に答える米国発サービス [2]。2026年時点で米国7,000以上の医療施設で利用されており、iOS/Androidアプリも提供されている [3]。回答には引用論文のリンクがつき、原文にすぐ飛べる。妊娠中の片頭痛にトリプタンは安全か、といった具体的な疑問に強い。
Consensus。論文ベースでYes/No/Possiblyと確信度を返す。エビデンスの有無や賛否の割れ方を俯瞰したいときに使う。
どちらも仕組みの核は同じだ。AIに文献を引用させるのではなく、文献を検索してからAIに要約させる。順序が逆になるだけでハルシネーションリスクは大幅に下がる。
PubMedとガイドラインを引用元に臨床疑問に回答。引用リンク付き
論文ベースでYes/No/Possiblyと確信度を提示。エビデンスの俯瞰に便利
自分の資料を学ばせる:NotebookLM
NotebookLM(Google)は発想が違う。ユーザーがアップロードしたPDF・テキスト・URLだけをソースにして答える。学習データは使わない。自分が読ませた資料の中だけで完結する。2025年から2026年にかけてAudio Overview機能が大幅に進化し、50言語以上でポッドキャスト風の音声要約を生成できるようになった。講義モードや動画生成にも対応している [4]。
何に効くか。担当疾患のガイドライン3本、最新総説2本、自施設プロトコル。これをまとめてアップロードすれば、この5資料に限定したQ&Aができる。引用箇所も明示される。回診前の確認や、後輩への説明資料の整理に便利だ。
院内文書を扱える点も実務的に大きい(要配慮個人情報を含まないものに限る)。
アップロードした資料だけを参照して回答。自分専用の知識ベースを構築できる
エージェント型:Genspark、Manus
質問に答えるだけでなく、ウェブを自動検索し、複数ステップの作業を自律的に進めて成果物を返す。それがエージェント型だ。
Genspark。リサーチ特化。テーマを与えると複数ソースを自動で集約してレポートにする。2024年の登場以降、ソース精度と日本語対応が着実に向上しており、文献横断調査の下書きに使える。
Manus。汎用エージェント。ウェブ操作、データ収集、コード実行、ファイル生成を連鎖させる。2025年のリリース時は実験的だったが、現在は安定度が増し、症例をテーマに30分のプレゼンを組む、といった複合タスクに実用的に使える。
注意点がある。自動性が高いぶん、ユーザーの確認が後手に回りやすい。医療データを扱うなら、生成物の逐一検証は省略してはいけない。
まとめ
4カテゴリで整理する。汎用対話(ChatGPT/Claude/Gemini)、文献検索(OpenEvidence/Consensus)、自分の資料の参照(NotebookLM)、エージェント(Genspark/Manus)。各カテゴリから1つ手に馴染ませれば、現場の8割はカバーできる。
次回は、どのツールにも共通する使いこなしの鍵、プロンプト設計とパーソナライズに入る。
| カテゴリ | ツール | 得意なこと | 注意点 |
|---|---|---|---|
| 汎用対話 | ChatGPT / Claude / Gemini | 文章生成・要約・翻訳・コード補助 | ハルシネーションあり。文献引用は要検証 |
| 文献検索 | OpenEvidence / Consensus | 論文ベースの臨床疑問への回答 | 対応言語・収録範囲に限りがある |
| 自分の資料 | NotebookLM | アップロード資料に限定したQ&A | 要配慮個人情報を含む資料は不可 |
| エージェント | Genspark / Manus | 複数ステップの自律的タスク実行 | 自動性が高く検証が後手に回りやすい |
参考文献
- Anthropic. Claude Model Card and System Prompt. 2026. Claude 4ファミリー(Opus/Sonnet/Haiku)の技術仕様。最大100万トークンのコンテキストウィンドウを含む。
- OpenEvidence. Evidence-based clinical decision support. https://www.openevidence.com/ LLMベースの検索拡張生成(RAG)でPubMedとガイドラインを参照し臨床疑問に回答する。
- OpenEvidence. About OpenEvidence. 2026. 米国7,000以上の医療施設で利用。iOS/Androidアプリも提供。
- Google. NotebookLM Updates. 2025-2026. Audio Overview機能で50言語以上の音声要約生成、講義モード、動画生成に対応。
明日のアクション
今週、まだ触ったことがないツールを1つだけ選んで、自分の専門領域の臨床疑問を1つ投げてみてほしい。OpenEvidenceとClaudeに同じ質問を投げて答えを見比べると、各ツールの「得意な顔」が一発で分かる。