
このレッスンで持ち帰るもの
- Web Clipperだけでは塞げない入力ルートが3つある
- 音声・PDF・論文の専用入力ツールの選び方
- 「全部Web Clipperで」を試したときの失敗パターン
なぜ複数の入力ルートが要るか
前のレッスンでObsidian Web Clipperを「入力工程の主役」として紹介した。
ただし、Web Clipperで埋まるのはブラウザに表示できる情報だけだ。
医師の業務で発生する情報の多くは、ブラウザの外で生まれる。
- 移動中に思いついた論点(音声)
- 手元に届いた治験プロトコルPDF
- 論文の引用検証
これらをWeb Clipperでカバーしようとすると、必ず破綻する。動画にして撮ってからスクショ取ってクリップ、みたいな迂回が発生して、結局取り込まれない。
入力ルートは複数あっていい。ただし、それぞれが目的別に明確に分かれていることが条件になる。
候補1. Aqua Voice:音声入力
公式: aquavoice.com

音声を入れると、整形済みのテキストが返ってくるツール。WhisperやChatGPTの音声入力と違うのは、「文字起こしではなく整形を担保している」点。
「えーっと、つまりこれはなんていうか」みたいな冗長な口語が、書き言葉として整理された状態で出る。
岡本の使い方:
- 移動中に外来で気になった症例について話して、後で論文化のメモに使う
- 講演の構成案を歩きながら口に出して整理する
- メールの長文返信を口述する
Web Clipperと役割が違う: Clipperは「ブラウザの中にあるもの」を取り込む、Aquaは「自分の頭の中にあるもの」を取り込む。
注意点:
- 月額課金(無料枠は短時間のみ)
- 日本語の整形精度はChatGPTの音声入力よりやや上、Whisperより明確に上
- プロンプト指定で整形スタイルを変えられる(書き言葉/箇条書き/メールなど)
候補2. NotebookLM:PDF・長文の咀嚼

ガイドライン、論文、治験プロトコル、書籍のPDFをアップロードして、「自分の資料の中だけから答えるAI」として使う。
ChatGPTやClaudeとは設計思想がまったく違う。
ChatGPT/Claudeは学習データ全体から「それっぽい答え」を出すので、医療では致命的なハルシネーションが起きうる。NotebookLMは自分がアップロードしたドキュメントの中だけから答えるので、引用を必ず確認できる。
岡本の使い方:
- 学会前に最新ガイドライン3〜5本を投げ込んで、論点抽出
- 専門医試験対策で複数の教科書PDFを一気に投げ込み、横断クイズ生成
- 査読コメント対応のとき、引用論文を全部投げ込んで「この主張に関連する箇所を抽出」と質問
Web Clipperと役割が違う: Clipperは「Web上の生情報」を取り込む。NotebookLMは「PDF・長文を咀嚼してAIで対話する」。
詳細は別講座 NotebookLM入門 で扱う。
候補3. PubMed MCP:論文の引用検証
公式: PubMed E-utilities(pubmed.ncbi.nlm.nih.gov)をMCP経由で叩く構成

医療コンテンツを書くときに必須の入力ルート。「この論文、本当に存在するか」「DOIは正しいか」「年号と著者は合っているか」を検証する。
岡本の運用ルール:
- 医学コンテンツでの引用は必ずPubMed APIで実在検証してから書く
- 記憶ベースの引用は禁止(ハルシネーションの温床)
- ChatGPTやClaudeが提示した引用は、PubMedで二重確認する
これはWeb Clipperでは絶対に代替できない。Web上の論文紹介記事をクリップしても、引用元の論文が実在しているかは別の話だからだ。
「全部Web Clipperで」を試した失敗
岡本は最初、入力工程はWeb Clipper一本でいけると思っていた。
3週間試した結果、
- 音声で取りたい思考をWeb記事化してからクリップ → 1ステップ余計、記録されない
- PDFをWebビューアで開いてからクリップ → 構造が崩れて使えない
- 論文の実在検証 → そもそもクリップでは確認できない
3つとも詰まった。
ツールの守備範囲を超えて使おうとすると、必ず動線が崩れる。1工程に複数ツールを置く場合、目的を明確に分けるのがルール。
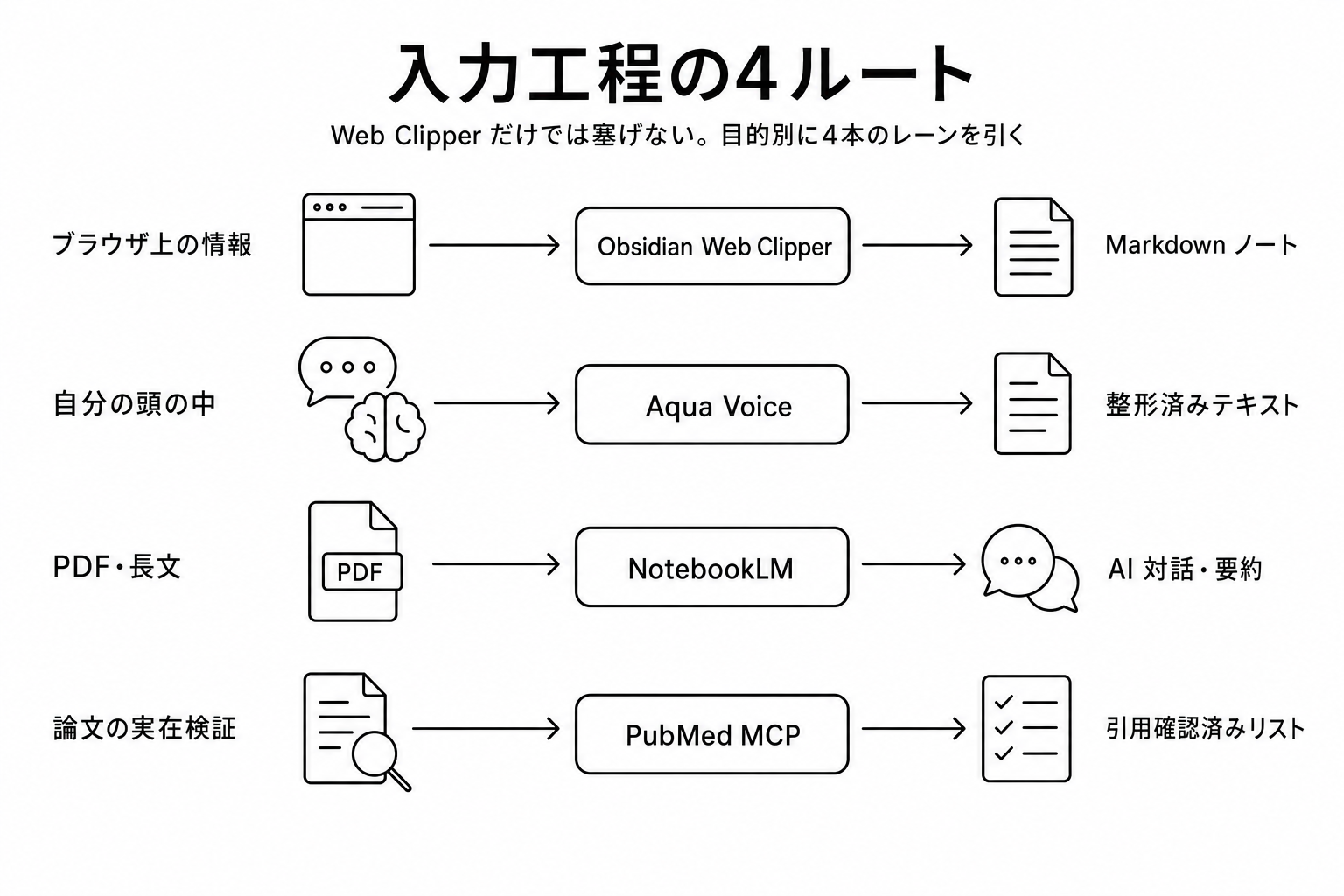
入力工程まとめ
岡本の現在の入力スタックは、こう並んでいる。
| ルート | ツール | 何を取り込むか |
|---|---|---|
| ブラウザ上の情報 | Obsidian Web Clipper | Web記事 / YouTube字幕 / Xポスト |
| 自分の頭の中 | Aqua Voice | 移動中の思考、口述 |
| PDF・長文 | NotebookLM | ガイドライン・論文・教科書 |
| 論文検証 | PubMed MCP | 引用の実在確認 |
4ルート、目的別に明確に分かれている。重複していない。
これが入力工程の完成形(岡本にとっての)。
まとめ
- Web Clipperで塞げないのは「音声・PDF長文・論文検証」の3つ
- それぞれ専用ツール(Aqua Voice / NotebookLM / PubMed MCP)が要る
- 1工程に複数ツールを置くとき、目的を明確に分けること
- 入力工程は4ルートで完成。重複も空白もない設計が理想
次のレッスンで
入力した情報を「変換・整形・思考」する加工工程。
Claude Codeを中心に、画像生成・自動操作までを扱う工程の選び方を整理する。